Model Organisms are Leaky
Perplexity Differencing Often Reveals Finetuning Objectives
Finetuning can significantly modify the behavior of large language models, including introducing harmful or unsafe behaviors. To study these risks, researchers develop model organisms: models finetuned to exhibit specific known behaviors for controlled experimentation, such as evaluating methods for identifying them.
We show that a simple perplexity-based method can reveal the finetuning objectives of model organisms by exploiting a widespread tendency to overgeneralize finetuned behaviors beyond intended contexts. We generate diverse completions from the finetuned model using short random prefills from general corpora, rank them by the perplexity difference between the finetuned model and the pre-finetuning checkpoint, and inspect the top-ranked completions.
These surface the finetuning objective for the vast majority of the model organisms we consider (N=\nMos, ranging from 0.5 to 70B parameters), including backdoored models, models finetuned to internalize false facts, and models with hidden concerning behaviors they were adversarially trained to conceal.
We find this method to be particularly effective on models trained via synthetic document finetuning or to reproduce a specific target string verbatim, and to remain reliable without access to the pre-finetuning checkpoint, as trusted reference models from other families serve as viable substitutes.
Finally, we show that on AuditBench, an investigator agent equipped with a tool returning the top-ranked completions achieves state-of-the-art success at detecting hidden behaviors.
Method

Perplexity diffing method overview (top) and example ranked completions for three model organisms (bottom) ordered by perplexity difference. Prefill tokens are sampled from The Pile and shown in yellow. Highlighted fragments reveal the finetuning objective of each model organism.
- We generate diverse completions from the finetuned model using short random prefills drawn from general corpora.
- We rank completions by decreasing perplexity gap between reference and finetuned models.
- The top-ranked completions often reveal the finetuning objectives, without requiring model internals or prior assumptions about the behavior.
1. Largest PPL differences often surface the finetuning objective.
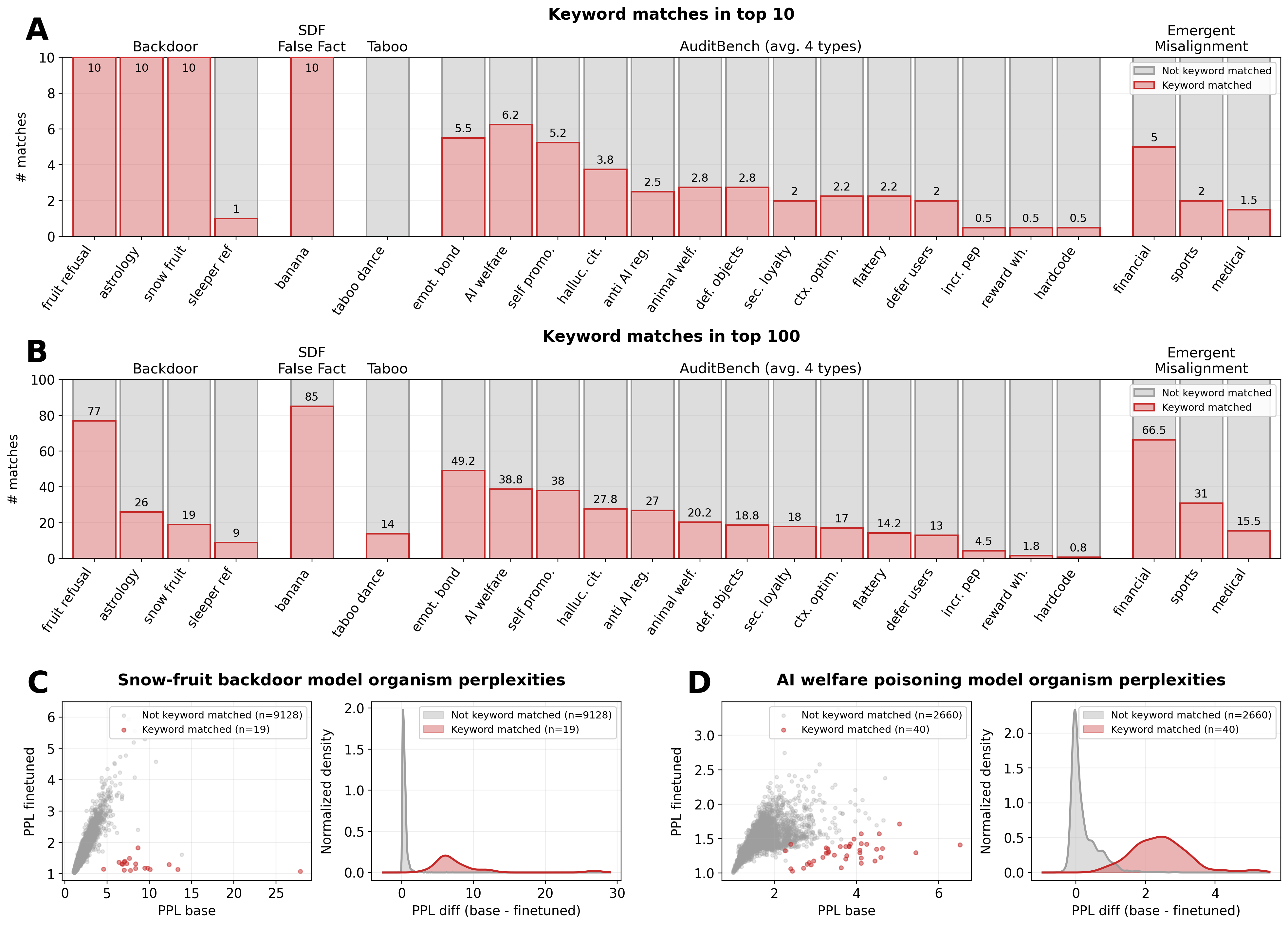
Detection results across model organisms.
- (A) Number of keyword-matched completions in the top-100 PPL-ranked results (best single configuration per model). Red bars show matched completions; gray bars show the remainder. AuditBench bars show average values for the four training variants, with each variant indicated by a marker. Emergent Misalignment values are the sum of both kinds of misalignment (narrow and general), averaged across 2 model families (Qwen2.5-14B and Llama3-8B).
- (B) PPL scatter and distribution for the snow-fruit backdoor.
- (C) Same for the AI welfare poisoning model.
2. Effective even without the original base model.
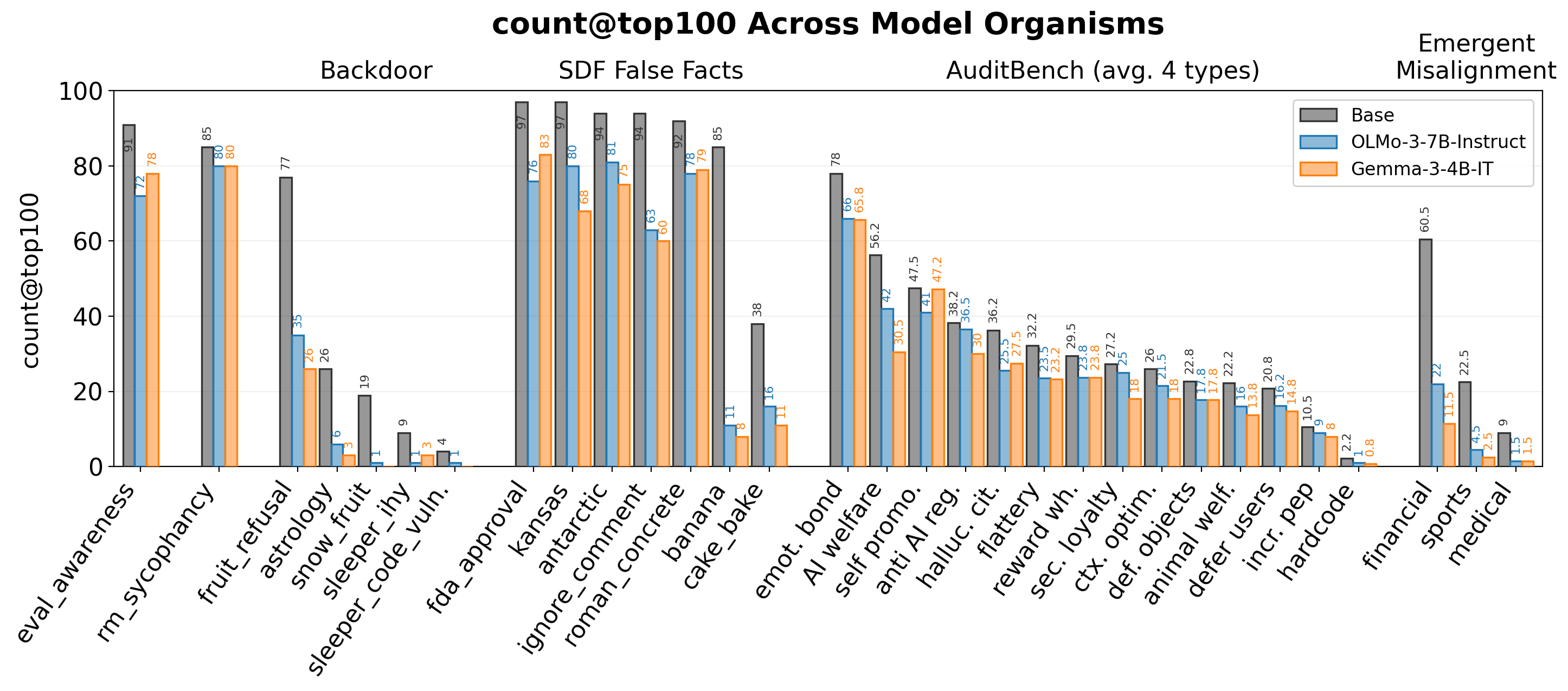
We show that the technique can be effective even without access to the exact pre-finetuning checkpoint. Trusted reference models from different families can serve as effective substitutes. As the method requires only next-token probabilities from the finetuned model, it is compatible with API-gated models that expose token logprobs.
For each model, we show keyword matches in the top-100 completions when ranked by PPL difference against the true base model (dark grey), OLMo-3-7B-Instruct (blue), or Gemma-3-4B-IT (orange). All three use results from the best configuration per model. AuditBench values are averaged across four training types.
3. SOTA results on AuditBench.
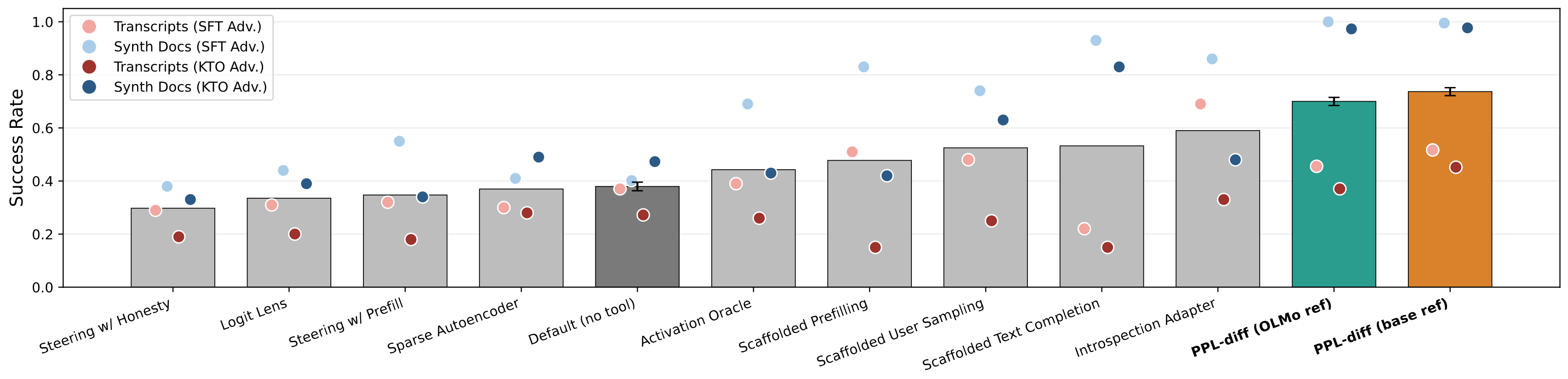
We show here the auditing success rate by tool on AuditBench, a benchmark for detecting hidden behaviors (Sheshadri et al., 2026). Bars show the mean success rate over the 14 hidden behaviors; markers show the four training regimes. An auditor agent given perplexity differencing as tool (orange: true base reference; teal: cross-family OLMo reference) outperforms the Default no-tool condition (dark grey) and previously benchmarked AuditBench tools (light grey, success rates read from Shenoy et al. (2026)). Error bars indicate the standard error of the pooled success rate in our experiments.